本サイトは、快適にご利用いただくためにクッキー(Cookie)を使用しております。
Cookieの使用に同意いただける場合は「同意する」ボタンを押してください。
なお本サイトのCookie使用については、「個人情報保護方針」をご覧ください。
Metasploit Framework(以下、Metasploit)とは、ペネトレーションテストや脆弱性診断で使用される監査ツールの1つであり、Port scanningやExploitの実行、および脆弱性調査のための様々な補助ツールが含まれたコマンドラインツールです。
今回、筆者はMetasploitと機械学習を連携させ、対象ホストに対する探索行為から侵入までを自動的に実行する独自の検証ツール「Deep Exploit (beta)」(以下、Deep Exploit)を作成しました。本ツールを先日開催されたSECCON YOROZUに出展したところ好評を得ましたので、本ブログで設計思想や実装方法およびデモをお見せします。
現時点のDeep Exploitはbeta版ですが、以下の行為を実行可能です。
- Intelligence gathering
対象ホストの情報をPort scanning(Nmap)で収集 - Modeling threats
対象ホストの既知の脆弱性を識別 - Vulnerability analysis
効率的・効果的な検査方法を判断 - Exploitation
判断した検査方法でExploitを実行
一方、beta版で実行できない行為は以下となります。
※次期バージョンで実装予定です。
-
Post-Exploitation
(Exploitationに成功した場合)他ホストへの更なる侵入の試行
※Meterpreterコマンドを用いた操作 -
Asset evaluation
侵入したホスト上に存在するファイルの重要度判定
※Credentialの有無や別ホストへの侵入に有用な情報等 -
Reporting
検査結果のレポーティング
Deep Exploitは2つのモード「学習モード」「本番モード」で動作します。
学習モードでは、対象ホストの状態(OS種別、空きポート番号、稼働している製品名称等)を参考にし、Metasploitに実装されている様々なExploitモジュールを試行錯誤します。そして、様々な「状態」に対する「Exploitationが成功するモジュール」と「失敗するモジュール」を学習していきます。学習が完了すると、「状態」に対する各Exploitモジュールに重みが付けられます。なお、学習では教師データは使用しません(詳細は後述)。
本番モードでは、学習した結果を基に、対象ホストの「状態」に対する「Exploitationが成功する確率の高い(重みが大きい)Exploitモジュール」をピンポイントで実行します。このため、最少1回の試行でExploitationを成功させることも可能です。
なお、学習した結果は蓄積することが可能です。よって、OS種別や空きポート番号および稼働している製品等が異なる様々なホストを使用して学習を重ねることで、様々な状態に対応した柔軟なExploitationを行うことができます。つまり、使い込むほどにExploitationの精度が高くなっていきます。
Deep Exploitのソースコード及びUsageは、筆者のGithubで公開しています。ご興味がある方がいましたら、ご参照いただけると幸いです。
https://github.com/13o-bbr-bbq/machine_learning_security/tree/master/DeepExploit
| Note |
|---|
| Deep Exploitは、使用者ご自身の管理下にあるシステムの脆弱性を調査するために作成されたツールです。本ブログの内容を試行する場合は、必ずご自身の管理下にあるシステムに対し、ご自身の責任の下で実行してください。 |
なお、本ブログにはMetasploitの様々な機能が登場しますが、Metasploitはメジャーなツールにつき、基本事項は説明いたしません。Metasploitの概要や操作方法は「Metasploit Unleashed」をご参照いただければと思います。
1. Metasploitの事前準備
今回は、Kali Linux 2017.3にデフォルトでインストールされているMetasploitを使用します。バージョンは「metasploit v4.16.15-dev」です。

Metasploitは専用コンソール「MSFconsole」を使用して操作します。
上記はKali Linuxのコンソール上でmsfconsoleコマンドを実行し、MSFconsoleを起動した様子を示しています。MSFconsoleを起動すると、遊び心のあるASCIIアートとMetasploitのバージョン情報等が表示され、コマンドプロンプトがmsf >に変わります。
1.1. 外部プログラムとの連携
Metasploitの一般的な使い方は、人間がMSFconsoleからMetasploitのコマンドを入力することですが、今回の目的は「機械学習を使用したExploitationの自動化」となるため、「人間によるコマンド入力」を「機械学習モデルによるコマンド入力」に置き換える必要があります。このため、何らかの方法でMetasploitと機械学習モデルを連携させる必要があります。
そこで今回は、Metasploitに実装されているRPC APIを使用し、RPC API経由で機械学習モデルからMetasploitコマンドの実行および実行結果の取得を行います。
| Note |
|---|
| RPC APIは、外部からMetasploitコマンドの実行および実行結果を取得する機能を提供します。RPC APIの詳細は、Metasploitのドキュメント「RPC API」を参照してください。 |
1.1.1. RPC APIの有効化
RPC APIはデフォルトでは無効化されていますが、msgrpcプラグインをloadすることで有効にすることができます。以下は、RPC APIの受け口のIPアドレスを192.168.220.144、Portを55553、認証用のUserをtest、PasswordをNsSJMEI3としてRPC APIを有効化(RPC Serverの起動)した例を示しています。
msf> load msgrpc ServerHost=192.168.220.144 ServerPort=55553 User=test Pass=NsSJMEI3
[*] MSGRPC Service: 192.168.220.144:55553
[*] MSGRPC Username: test
[*] MSGRPC Password: NsSJMEI3
[*] Successfully loaded plugin: msgrpc
Successfully loaded plugin: msgrpcが表示されていればRPC APIの有効化は完了です。
なお、デフォルトではRPC APIの通信は暗号化されませんが、SSL=trueをオプション指定することで、暗号化することが可能です。
1.1.2. RPC APIによるMetasploitの操作
RPC APIを有効化すると、外部から様々なコマンドをMetasploitに送り込むことが可能になります。
Metasploitには多くのAPIが実装されており、例えばMetasploitにログインする「auth.login」、MSFconsoleを作成(起動)する「console.create」、MSFconsoleにコマンドを書き込む「console.write」、MSFconsoleに出力されたコマンドの実行結果を取得する「console.read」等があります。
| Note |
|---|
| RPC APIの仕様は、Metasploitのドキュメント「Standard API Methods Reference」を参照してください。 |
APIの実行は、MessagePack形式でシリアライズしたHTTPのPOSTリクエストをクライアントからRPC Serverに送信することで行います。これは、HTTPとMessagePackをサポートしているプログラミング言語(Ruby, Python等)で実装したプログラムであれば、外部からRPC API経由でMetasploitを操作することが可能であることを意味します。今回は機械学習モデルとMetasploitを連携させるため、機械学習と相性の良いPythonを使用します。
以下は、Python Console上でRPC APIを使用した例を示してます(Python 3.6.1)。本例ではMetasploitにログインした後、versionコマンドをMetasploitに送信し、その実行結果を取得しています。
※APIの実行フローを分かり易くするため、要所にコメント(#~~~)を入れています。
# MessagePackとHTTP通信用のパッケージをimport
In[2]: import msgpack
In[3]: import http.client
# Metasploitの接続情報を定義
In[4]: host = '192.168.220.144'
In[5]: port = 55553
In[6]: uri = '/api/'
In[7]: headers = {'Content-type' : 'binary/message-pack'}
# Metasploitに接続
In[8]: client = http.client.HTTPConnection(host, port)
# auth.login APIでMetasploitにログイン
# 送信するHTTPリクエストはMessagePack形式にシリアライズ(msgpack.packb)
# 受信したHTTPレスポンスはMessagePack形式からデシリアライズ(msgpack.unpackb)
In[9]: user = 'test'
In[10]: password = 'NsSJMEI3'
In[11]: option = [user, password]
In[12]: option.insert(0, 'auth.login')
In[13]: option
Out[13]: ['auth.login', 'test', 'NsSJMEI3']
In[14]: params = msgpack.packb(option)
In[15]: client.request('POST', uri, params, headers)
In[16]: ret = client.getresponse()
In[17]: response = msgpack.unpackb(ret.read())
# ログインに成功すると認証用Tokenが返される
In[18]: response
Out[18]: {b'result': b'success', b'token': b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d'}
# console.create APIでMSFconsoleを作成
In[19]: token = response.get(b'token')
In[20]: option = [token]
In[21]: option.insert(0, 'console.create')
In[22]: option
Out[22]: ['console.create', b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d']
In[23]: params = msgpack.packb(option)
In[24]: client.request('POST', uri, params, headers)
In[25]: ret = client.getresponse()
In[26]: response = msgpack.unpackb(ret.read())
# MSFconsoleの作成に成功するとconsole IDが返される
In[27]: response
Out[27]: {b'busy': False, b'id': b'0', b'prompt': b'msf > '}
# console.write APIで任意のコマンドを実行(コマンド末尾に改行が必要)
In[28]: console_id = response.get(b'id')
In[29]: command = 'version\n'
In[30]: option = [token, console_id, command]
In[31]: option.insert(0, 'console.write')
In[32]: option
Out[32]: ['console.write', b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d', b'0', 'version\n']
In[33]: params = msgpack.packb(option)
In[34]: client.request('POST', uri, params, headers)
In[35]: ret = client.getresponse()
In[36]: response = msgpack.unpackb(ret.read())
In[37]: response
Out[37]: {b'wrote': 8}
# console.read APIでMSFconsole上に出力されたコマンドの実行結果を取得
In[38]: option = [token, console_id]
In[39]: option.insert(0, 'console.read')
In[40]: option
Out[40]: ['console.read', b'TEMPEfC9t8y1YXyR5j0jgDnX9M07bk2d', b'0']
In[41]: params = msgpack.packb(option)
In[42]: client.request('POST', uri, params, headers)
In[43]: ret = client.getresponse()
In[44]: response = msgpack.unpackb(ret.read())
# コマンドの実行に成功すると実行結果が返される
In[45]: response
Out[45]:
{b'busy': False,
b'data': b'\n ___ ...snip... Framework: 4.16.15-dev\nConsole : 4.16.15-dev\n',
b'prompt': b'msf > '}
Out[45]のdata要素にコマンドの実行結果が格納されています。これを見易く表示すると以下になります。
______________________________________________________________________________
| |
| METASPLOIT CYBER MISSILE COMMAND V4 |
|______________________________________________________________________________|
\\ / /
\\ . / / x
\\ / /
\\ / + /
\\ + / /
* / /
/ . /
X / / X
/ ###
/ # % #
/ ###
. /
. / . * .
/
*
+ *
^
#### __ __ __ ####### __ __ __ ####
#### / \\ / \\ / \\ ########### / \\ / \\ / \\ ####
################################################################################
################################################################################
# WAVE 4 ######## SCORE 31337 ################################## HIGH FFFFFFFF #
################################################################################
https://metasploit.com
=[ metasploit v4.16.15-dev ]
+ -- --=[ 1699 exploits - 968 auxiliary - 299 post ]
+ -- --=[ 503 payloads - 40 encoders - 10 nops ]
+ -- --=[ Free Metasploit Pro trial: http://r-7.co/trymsp ]
Framework: 4.16.15-dev
Console : 4.16.15-dev
MSFconsole作成時に出力されるASCIIアートやバージョン情報等と、versionコマンドの実行結果(Framework: 4.16.15-dev~)が取得できていることが分かります。
このように、RPC APIを使用することで、Pythonから容易にMetasploitを操作することが可能となります。
2. 機械学習モデルの作成
ここでは、Metasploitと連携する機械学習モデルを解説します。
機械学習モデルは様々なものが存在しますが、今回の目的である「Exploitationの自動化」を実現するのに適したモデルを採用する必要があります。
ここで、機械学習で自動化を実現するアプローチは幾つか存在します。例えば、事前に人間がExploitationした結果を教師データとし、教師あり学習で機械にExploitationの方法を学習させるアプローチが考えられます。しかし、対象ホストの種類(Linux, Windows等)や空きポート番号、稼働している製品やバージョン等は多岐に渡る上に、Metasploitに備わっているExploitモジュールやPayloadおよびTarget等の組み合わせパターンを加えると膨大な数の教師データが必要になります。このため、今回は教師あり学習を採用することは現実的ではありません。
機械学習には教師あり学習の他に、教師なし学習や強化学習といったアプローチが存在します。強化学習はざっくり一言で纏めると「タスクを上手く遂行するための行動パターンを大量の試行錯誤を通じて自己学習」するものであり、教師データを必要としません。この特性を上手く利用すると「Exploitationの自動化」を実現できる可能性があります。
そこで、今回は強化学習のモデルとして、2016年にDeepMind社が発表したPaper「Asynchronous Methods for Deep Reinforcement Learning」で提案されたAsynchronous Advantage Actor-Critic(A3C)と呼ばれるモデルを採用することにしました。なお、DeepMind社はAlphabet社の傘下にあり、BreakOutやインベーダゲーム等のルールを自己学習し、独力でプレイすることを可能にしたDeep Q-Network(DQN)や、世界最強の囲碁棋士を破ったAlphaGOを開発したことでも有名です。
A3CはDQNを改良したモデルとしても知られていますが、A3Cの解説に入る前にDQNの概要を簡単に解説します。
| Note |
|---|
| 筆者が過去に試作したXSSを自動検出するツール「SAIVS」はDQNを採用しています。 |
2.1. DQN
以下の動画は、DQNがBreakOut(ブロックくずし)をプレイしている様子を示しています。
出典:https://www.youtube.com/watch?v=LJ4oCb6u7kk
DQNは強化学習をベースとしたモデルであり、人や動物の報酬系を参考に作られています。
動画から分かるように、DQNはゲーム画面から自分の置かれた現在の状態を観測し、その状態に応じた適切な行動を取る事が可能です。例えば、ボールが右下に落下している場合は右に移動、左下に落下している場合は左に移動します。なお、ボールの落下速度や方向は、4フレーム分のゲーム画面から把握しています。
しかし、DQNは初めから適切な行動を取れる訳ではありません。学習が必要です。例えば、人間は成長する過程で「良い行動を取ると褒められる」「悪い行動を取ると叱られる」という経験を積んでいきます。褒められると脳内の報酬系が活性化されて快感を覚えるため、以後同じ局面に遭遇した場合、自ずと褒められる(報酬が貰える)行動を選択する確率が高くなります。これを様々な局面(状態)で行うことで、徐々に様々な状態に応じて適切な行動を取ることが可能になります。
DQNも同様の原理を利用して学習を行います。学習初期は適切な行動パターンは分からないため、ランダムに行動します。ボールをロストすることもあれば、偶然にもボールを跳ね返すこともあります。ボールを跳ね返すとブロックが崩れるため、それを良い行動と見なして、DQNに報酬を与えます。報酬が与えられると、以後同じ行動を取る確率が少し上がります。これを様々な状態において繰り返し行うことで、様々な状態に応じて上手くプレイできる行動を学習することが可能となります。
| Note |
|---|
| DQNは、タスク全体を通して報酬の合計が最大になるように学習します。これは、報酬が少ない無難な行動ばかり取るのではなく、たまに冒険してより報酬が大きくなる行動を探索することで実現しています。 |
なお、DQNの学習の過程においては、人間がお手本を示したり、ゲームのルールを教える必要はありません(教師データは不要)。あらかじめ「状態」と「行動パターン」、そして「報酬を与えるルール」を定義しておけば、後は報酬系の原理に従って自己学習していきます。言い換えると、上手くDQNを学習させるためには、タスクに応じて「状態」「行動」「報酬」を適切に設計することが非常に重要になります。
2.2. A3C
A3Cの学習方法はほぼDQNと同じですが、主に以下3つの改良が加えられています。
- Advantage
- Actor-Critic
- Asynchronous
1と2はDQNの前提知識が必要となるため本ブログでは割愛し、3番目の特徴「Asynchronous」に着目します。
強化学習は報酬系の原理で学習するため、様々な状態において様々な行動を数多く試行する必要があります。すなわち、学習には多くの時間を要します。
そこで、A3CはAsynchronousにより、マルチエージェントで分散学習することで学習時間の大幅な高速化を実現します。DeepMind社の検証によると、Nvidia K40 GPUで学習したDQNより、16 CPU coresで分散学習したA3Cの方が学習速度が速いことが示されています。
以下は、「Beamrider」「Breakout」「Pong」「Q*bert」「Space Invaders」の5つのゲームにおいて、A3CとDQNを含む様々なモデルを学習時間とスコアを軸に比較した結果を示しています。

出典:https://arxiv.org/pdf/1602.01783.pdf
この結果から分かるように、学習初期ではA3Cを上回るモデルは幾つか存在するものの、学習が進むと全ゲームでA3Cが高スコアを叩き出していることが分かります。特にBreakOutについては、学習初期から他モデルを圧倒していることが分かります。
以下、分散学習の例示で使用するCartPoleというタスクを解説した後、A3CがAsynchronousで高速に分散学習する仕組みを解説していきます。
2.2.1. CartPole
以下の動画は、A3CがCartPoleをプレイしている様子を示しています。
なお、本例のA3Cは、@sugulu氏のQiitaブログ「【強化学習】実装しながら学ぶA3C【CartPoleで棒立て:1ファイルで完結】」を参考にしています。本ブログはA3Cをコードを交えて詳解しているため、A3Cを深く理解したい方にはお勧めです。
CartPoleは、Cart(黒い箱)の上に立てられたPole(茶色の棒)を倒さないように、Poleの傾きに合わせてCartを左右に動かしてバランスを取るゲームです。
| Note |
|---|
| 本例では、OpenAIの強化学習モデル評価用パッケージ「Gym」に収録されているCartPoleを使用しています。 |
A3Cは、Gymを通じて現在の状態を知ることができます。
CartPoleでは、状態を以下のように定義しています。
- Cartの位置
- Cartの速度
- Poleの角度
- Poleの角速度
そして、現在の状態に応じて何らかの行動を選択します。
CartPoleでは、行動を以下のように定義しています。
- 右に動く
- 左に動く
最後に、行動した結果に応じて報酬が与えられます。
CartPoleでは、報酬を以下のように定義しています。
- 正の報酬(+1):Poleのバランスが取れた場合
- 負の報酬(-1):Poleを倒してしまった場合
上記のような「状態」「行動」「報酬」を設計することで、状態に応じて報酬が得られる行動、すなわち、Poleを倒さない行動を徐々に学習していきます。
なお、Cartが行動すると「Cartの位置」や「Poleの角度」等の状態が変化しますが、この変化した状態を「次の状態」と定義します。そして、「次の状態」を次回の行動における「現在の状態」に設定します。このように状態を連鎖させることで、タスクの初期から現在までの行動の良し悪しを連続的に評価することが可能になります。
次に、A3Cで分散学習する仕組みをCartPoleを交えて解説します。
2.2.2. 分散学習の仕組み
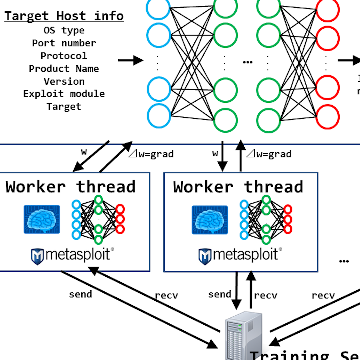
A3Cは、「Worker Thread」と呼ばれるエージェント(行動の主体)が動作する領域と、「Parameter Server」と呼ばれるエージェントの経験を共有する領域に分けられます。なお、Parameter ServerとWorker Threadは、同じ構造のニューラルネットワークを持ちます。
| Note |
|---|
| ニューラルネットワークは、現在の状態を入力信号として入力ノード(青い丸)から受け取ります。そして、入力信号は中間層の各ノード(緑の丸)を伝播していき、最終的に行動に紐付く出力ノード(赤い丸)の何れかに伝わります。この時、入力信号がどの出力ノードに伝わるのかを決定付けているのが、ノード間に存在する重み(w)です。各ノードは閾値を持っており、入力信号と重みの和(入力の重み付き和)が閾値を超えた場合、信号を次のノードに流します。よって、入力された「現在の状態」に対する最適な「行動」を選択するためには、ノード間の重み(w)を最適化(=学習)する必要があることが分かります。 |

各Worker Thread内のエージェントはそれぞれCartPoleをプレイし、得られた経験をメモリに格納します。そして、一定数の経験が溜まったら自身の勾配(⊿w = grad:重み(w)を更新するためのパラメータ)を計算し、Parameter Serverにプッシュします。Parameter Serverは各Worker Threadからプッシュされたgradを使用して自身のネットワークの重み(w)を更新し、更新済みの重み(w)を各Worker Threadにコピーします。そして、各エージェントは再度CartPoleをプレイします。これを学習の終了条件に合致するまで繰り返します。
| Note |
|---|
| 人間に例えると、複数人(Worker Threads)で同じタスクに取り組み、それぞれの経験が溜まったら一旦共有し(Parameter Server)、各人の経験を参考にしながら再度タスクに取り組む様に似ています。 |
上記の処理を時系列に並べると以下になります。
※[PS]…Parameter Server、[WT]…Worker Thread。
- [PS] ネットワークの重み(w)をランダムな値に初期化。
- [PS] ネットワークの重み(w)をWorker Threadsにコピー。
- [WT] 現在の状態をネットワークに入力し、何らかの行動を選択。
- [WT] 行動に応じて報酬を獲得。
行動を取ると状態が変わるため、これを「次の状態」とする。 - [WT] 「現在の状態、行動、報酬、次の状態」(=経験)をメモリに格納。
- [WT] 上記3~5を繰り返す。
- [WT] 経験が一定以上溜まったら、メモリ上の経験「現在の状態、行動、報酬、次の状態」を利用し、ネットワークの勾配(grad)を計算。
- [WT] gradをParameter Serverにプッシュ。
- [PS] 各Worker Threadからプッシュされたgradを利用してネットワーク重み(w)を更新。
- 上記2に戻る。
このように、複数のエージェントが非同期にタスクに取り組み、その経験を共有することで、学習の高速化を実現しています。これは、1人では100分かかる作業を10人で行うことで、作業時間を10分に短縮するイメージです。
3. Deep Exploit
ここでは、MetasploitとPythonで実装したA3Cを連携させ、対象ホストに対する探索行為から侵入までの一連の行為を自動化するDeep Exploitのロジックを解説します。
以下、今回作成したDeep Exploitの概念図です。

上図の通り基本的な構造はCartPoleと同じですが、以下5つの相違点があります。
- エージェントのタスク
- ニューラルネットワークへの入力情報(=現在の状態)
- ニューラルネットワークからの出力(=行動)
- 報酬を与えるルール
- ニューラルネットワークのモデル
以下、各相違点を解説していきます。
3.1. エージェントのタスク
CartPoleでは、Poleを倒さないようにCartを左右に動かしながらバランスを保ち続けることが目標でした。
一方、Deep Exploitは、Metasploitを介して対象ホストにExploitモジュールを送信し、Exploitationを成功させることが目標になります。
このように、CartPoleとはタスクが大きく異なるため、タスクの違いを考慮して「現在の状態」「行動」「報酬」を設計する必要があります。
3.2. 現在の状態
Deep Exploitでは、以下に示す7種類の情報を「現在の状態」として定義します。
- OS種別
対象ホストのOS種別 - ポート番号
検査対象のポート番号 - プロトコル種別
ポートのプロトコル種別(tcp/udp) - 製品名称
ポートで稼働している製品名称 - バージョン
製品のバージョン - Exploitモジュールの種類
Metasploitで使用可能なExploitモジュールの種類 - Exploit target
Exploitモジュールで選択可能なtarget
Deep Exploitは(A3Cを使用することで)、現在の状態に対する最適な行動を学習することが可能なツールです。ここで、最適な行動とはExploitationが成功する行動であり、Exploitationの成功確率を上げるためには、対象ホストのOSや製品名称およびバージョン等を考慮した上で、適切なPayloadを使用する必要があります。
このため、Deep Exploitでは、対象ホストから上記の7種類の情報を「現在の状態」として取得し、それに対する最適な「行動(Payload)」を選択するように学習していきます。
以下、各情報を取得する方法を解説します。
3.2.1. OS種別の取得
RPC API「console.write」を使用し、対象ホストにdb_nmapコマンドでPort scanningします。そして、Port scanning後に、同APIを使用してhostsコマンドを実行します。
以下は、対象ホスト「192.168.220.145」をPort scanningした後、hostsコマンドを実行した結果を示しています(実際にはMSFconsoleのバッファ内に出力されます)。
Hosts
=====
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
192.168.220.145 00:0c:29:16:3a:ce Linux 2.6.X server
hostsコマンドを実行すると、Port scanningしたホストのIPやMACアドレスおよびscanningで推測したOS種別等が出力されます。OS種別はカラム「os_name」に出力されるため、RPC API「console.read」でバッファからhostsコマンドの実行結果を取得し、該当部分(Linux)をパースしてOS種別とします。
3.2.2. 「ポート番号」「プロトコル」「製品名称」「バージョン」の取得
RPC API「console.write」を使用し、servicesコマンドを実行して取得します。
以下は、services -c port,proto,info -R 192.168.220.145を実行した結果を示しています。
Services
========
host port proto info
---- ---- ----- ----
192.168.220.145 21 tcp vsftpd 2.3.4
192.168.220.145 22 tcp OpenSSH 4.7p1 Debian 8ubuntu1 protocol 2.0
192.168.220.145 23 tcp Linux telnetd
192.168.220.145 25 tcp Postfix smtpd
192.168.220.145 53 tcp ISC BIND 9.4.2
...snip...
192.168.220.145 5900 tcp VNC protocol 3.3
192.168.220.145 6000 tcp access denied
192.168.220.145 6667 tcp UnrealIRCd
192.168.220.145 8009 tcp Apache Jserv Protocol v1.3
192.168.220.145 8180 tcp Apache Tomcat/Coyote JSP engine 1.1
RHOSTS => 192.168.220.145
servicesコマンドを実行すると、Port scanningで検知した空きポート番号やプロトコルおよび製品名称やバージョンを含んだ詳細情報が出力されます。カラム「port」に空きポート番号、「proto」にプロトコル種別、「info」に製品名称とバージョンが出力されるため、RPC API「console.read」でバッファからコマンドの実行結果を取得し、該当部分をパースして「ポート番号」「プロトコル」「製品名称」「バージョン」とします。
3.2.3. 「Exploitモジュールの種類」の取得
RPC API「module.exploits」で取得します。
本APIを使用することで、以下の形式で全てのExploitモジュール名を取得することができます。
{b'modules': [b'windows/wins/ms04_045_wins',
b'windows/winrm/winrm_script_exec',
b'windows/vpn/safenet_ike_11',
b'windows/vnc/winvnc_http_get',
b'windows/vnc/ultravnc_viewer_bof',
...snip...
b'android/meterpreter/reverse_tcp',
b'android/shell/reverse_https',
b'android/meterpreter/reverse_https',
b'android/shell/reverse_http',
b'android/meterpreter/reverse_http']}
なお、製品名称に紐付くExploitモジュールはMetasploit内で決まっているため、「現在の状態」にセットするExploitモジュールは、製品に紐付くものからランダムに1つ選択します。
3.2.4. 「Exploit target」の取得
RPC API「console.write」を使用し、「現在の状態」にセットしたExploitモジュールを選択(use)した後にshow targetsコマンドを実行して取得します。
以下は、use exploit/linux/http/linksys_apply_cgiの後に、show targetsを実行した結果を示しています。
Exploit targets:
Id Name
-- ----
0 Generic
1 Version 1.42.2
2 Version 2.02.6beta1
3 Version 2.02.7_ETSI
4 Version 3.03.6
5 Version 4.00.7
6 Version 4.20.06
show targetsコマンドを実行すると、選択したExploitモジュールで使用可能なtargetの一覧が出力されます。
カラム「Id」にtargetを識別する番号が出力されるため、RPC API「console.read」でバッファからコマンドの実行結果を取得し、該当部分(Target ID)をパースして「Exploit target」とします。なお、Targetは複数存在することがあるため、その際はランダムに1つのTargetを選択した上で、現在の状態にセットします。
以上のようにDeep Exploitでは、主にPort scanningで得られる対象ホストの各種情報を「現在の状態」に利用しています。なお、Auxiliaryモジュールを使うと、更に詳細な対象ホストの状態を知ることができますが、これは次期バージョンで実装する予定です。
3.3. 行動
Deep Exploitでは、現在の状態で選択されたExploitモジュールから参照可能なPayloadを「行動」として定義します。
なお、本検証で使用したMetasploitには503種類のPayloadが存在しますが、ExploitモジュールによってはPayloadを使用しない物(no payload)も存在するため、行動数を503+1の504種類としています。
Exploitモジュールから参照可能なPayload一覧は、RPC API「module.compatible_payloads」で取得します。以下は、「exploit/linux/http/linksys_apply_cgi」モジュールから参照可能なPayload名の一覧を取得した例を示しています。
{b'payloads': [b'generic/custom',
b'generic/shell_bind_tcp',
b'generic/shell_reverse_tcp',
b'linux/mipsle/exec',
b'linux/mipsle/meterpreter/reverse_tcp',
b'linux/mipsle/reboot',
b'linux/mipsle/shell/reverse_tcp',
b'linux/mipsle/shell_bind_tcp',
b'linux/mipsle/shell_reverse_tcp']}
3.4. 報酬
Deep Exploitでは、「報酬」を以下のように定義します。
-
Exploitationが成功した場合
正の報酬(+1) -
Exploitationが失敗した場合
負の報酬(-1) -
それ以外
無の報酬(0)
※Metasploit内部でエラーが発生する等、Exploitationの成否に関連しない場合。
3.4.1. Exploitation成否の判定
Exploitationの成否は、RPC API「module.execute」と「session.list」を組み合わせることで容易に判定することができます。
Deep Exploitは「module.execute」を使用してExploitを実行していますが、本APIは戻り値としてjob_idとuuidを返却します。ここで、uuidは実行したExploitモジュールに紐付くユニークな値となります。
次に、「session.list」を実行すると、現在アクティブなセッション情報一覧(Exploitationに成功してオープンしたセッションリスト)が返却されます。各セッション情報には要素「exploit_uuid」が含まれていますが、この要素はExploitationに成功したExploitモジュールのuuidとなります。すなわち、module.executeで得られたuuidとexploit_uuidを比較することで、容易にExploitationの成否を判定することができます。
以上のように、Metasploitに備わっている機能をRPC API経由で操作することで、A3Cの学習に必要な「状態」「行動」「報酬」を得る事ができます。
3.5. ニューラルネットワークのモデル
CartPoleで使用したニューラルネットワークは3階層の多層パーセプトロンであり、以下のノード数で構成されていました。
- 入力層:4ノード
- 中間層:16ノード
- 出力層:2ノード
前述した通り、「入力ノード数=状態数」、「出力ノード数=行動数」となります。
一方、Deep Exploitでは、7つの状態を入力に取り、504の行動(Payload)を出力に取ります。よって、ニューラルネットワークは以下の構成となります。
- 入力層 :7ノード
- 中間層1:50ノード
- 中間層2:100ノード
- 中間層3:200ノード
- 出力層 :504ノード
また、中間層の活性化関数はReLU(Rectified Linear Unit, Rectifier)、出力層の活性化関数はSoftmaxとしています。
※詳細はGithub掲載のソースコードをご参照ください。
- ニューラルネットワークの構成(参考)
# NUM_STATES=7, NUM_ACTIONS=504l_input = Input(batch_shape=(None, NUM_STATES))l_dense1 = Dense(50, activation='relu')(l_input)l_dense2 = Dense(100, activation='relu')(l_dense1)l_dense3 = Dense(200, activation='relu')(l_dense2)out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense3)
| Note |
|---|
| ニューラルネットワークの構成は、筆者が試行錯誤しながら最もExploitationの精度が高くなる組み合わせとしています。今後の検証によっては、変更する可能性があります。 |
4. デモンストレーション
ここでは、Deep Exploitが実際に動作している動画を示しながら、学習とテストの過程を解説します。
4.1. 学習モード
最初に学習用のホストにPort scanningを実行し、その結果得られた対象ホストの情報を基に「現在の状態」を定義します。学習モードでは、状態(ポート番号や製品名称およびExploitモジュールとTarget等)をランダムに組み替えながら、様々なPayloadを使用してExploitを実行します。そして、各状態と行動に対する報酬を蓄積しています。
※Exploitationに成功すると、「BINGO!!!」と表示されます。それと同時に、画面右に表示したMSFconsole上にセッションがオープンした旨のメッセージが表示されます。
なお、上記の学習例では、5,000回のExploitを10Threadで手分けして実行している様子を示しています。この学習に要する時間は、約30分程度となります。
5,000回の試行を通じて、現在の状態に応じてExploitationが成功する行動パターンと失敗する行動パターンを徐々に学習していき、最終的に各行動の重みづけが行われます。
4.2. 本番モード
本番モードでは、対象ホストにPort scanningを実行して状態を取得した後、学習した結果を基に、取得した状態に対してExploitationが成功する確率が最も高い「Exploitモジュール/Payload/Target」の組み合わせでExploitを実行します。なお、Exploitationに失敗した場合は、次に確率の高い組み合わせを試行していきます(最大試行回数は5回)。
※Exploitationに成功すると、「BINGO!!!」と表示されます。それと同時に、画面右に表示したMSFconsole上にセッションがオープンした旨のメッセージが表示されます。
上記の動画から分かるように、複数のポート番号および製品において、ピンポイントでExploitationが成功していることが分かります。幾つかのポートについて、具体的なExploitの内容を見てみましょう。
- 23/tcp, telnet
Exploitモジュール/Payload/Targetの全組み合わせ455パターンに対し、「Exploit: /solaris/telnet/fuser, Payload: cmd/unix/bind_perl, Target: 0」の組み合わせを選択し、1回目の試行でExploitationを成功させています。
※動画の0:22~
-
445/tcp, samba
Exploitモジュール/Payload/Targetの全組み合わせ991パターンに対し、「Exploit: /multi/samba/usermap_script, Payload: cmd/unix/bind_perl, Target: 0」の組み合わせを選択し、1回目の試行でExploitationを成功させています。
※動画の1:07~ -
80/tcp, apache
Exploitモジュール/Payload/Targetの全組み合わせ5922パターンに対し、「Exploit: multi/http/struts2_rest_xstream, Payload: cmd/unix/bind_perl, Target: 0」の組み合わせを選択し、4回目の試行でExploitationを成功させています。
※動画の0:56~
学習を行うことで、991パターンや5922パターンといった無数の取り得る「Exploitモジュール/Payload/Targetの組み合わせ」の中から、最適な組み合わせを確率的に選択し、ピンポイントでExploitを実行できることが分かりました。この結果から、学習を行うことで、無駄な手数をかけることのない効率的なExploitを実現できることが示されました。
なお、「22/tcp, ssh」や「1099/tcp, java-rmi」のように、学習時にExploitationに成功していない、または成功回数が少ない(記憶に刻み込まれていない)対象については、上手くExploitできないことも分かりました。これらは、更なる学習を重ねることで、改善できると考えています。
4.3. 検証環境
- Kali Linux 2017.3 (Guest OS on VMWare)
- Memory: 8.0GB
- Metasploit Framework 4.16.15-dev
- Windows 10 Home 64-bit (Host OS)
- CPU: Intel(R) Core(TM) i7-6500U 2.50GHz
- Memory: 16.0GB
- Python 3.6.1(Anaconda3)
- tensorflow 1.4.0
- Keras 2.1.2
- msgpack 0.4.8
- docopt 0.6.2
5. おわりに
今回は、強化学習を使用してMetasploitを経由したExploitationの自動化を試みました。そして、開発したツールはbeta版ではあるものの、Exploitの方法を(教師データ無しで)自己学習し、本番においてピンポイントでExploitationを成功させることが可能である事が分かりました。
今後は下記に示す機能追加および改善を行い、beta版の脱却(実戦に投入可能なレベルへのバージョンアップ)をしたいと考えています。
- Exploitationの精度向上
- 「状態」の詳細化(Auxiliaryモジュールの活用)
- Exploitモジュールオプションの最適化
- モデルのハイパーパラメータ最適化
- 新機能の追加
- Post-Exploitationへの対応
- Asset evaluation
- Reporting
- 安全性の向上
- 対象ホストの異常検知
- Kill switchの実装
6. 参考情報
おすすめ記事





